What's in this lesson
You'll learn the foundations of classification and the K-Nearest Neighbors (KNN) algorithm.
Why this matters
KNN is one of the most intuitive algorithms, showing exactly how machines use historical data patterns to make predictions about new, unknown data.
The Neighborhood Analogy

Imagine you just moved to a brand new city. You want to know if a specific block is a quiet, family-friendly area or a noisy, bustling nightlife hub.
You don't have a map. What's the easiest way to find out?
This is exactly how K-Nearest Neighbors works.
Classification: Sorting the World

In Machine Learning, we often want the computer to predict something based on data.
When the prediction is a category (like "Apple" vs "Orange", or "Spam" vs "Not Spam"), it is called Classification. When the prediction is a number (like price or temperature), it is called Regression.
Weighing the Odds

How does a model actually choose a category? The ideal mathematical approach is the Bayes Decision Rule.
It simply says: "Calculate the probability of every category, and pick the one with the highest probability." But calculating exact probabilities for every possible scenario is often impossible.
Click the hotspots below to see why we need practical algorithms like KNN instead of pure Bayes:
Enter K-Nearest Neighbors (KNN)

Instead of calculating complex global probabilities, KNN is delightfully lazy. It memorizes the training data and only does work when it's time to make a prediction.
Explore the 3 steps of KNN below:
The Power of 'K'

The "K" in KNN is a number you choose. It stands for how many neighbors get a vote.
If K=3, the 3 closest neighbors vote. If 2 are Blue and 1 is Red, the new point is classified as Blue.
Knowledge Check
If we want an AI model to predict whether a customer will "Buy" or "Not Buy" a product, what type of problem is this?
Smooth or Jagged? (Overfitting vs Underfitting)
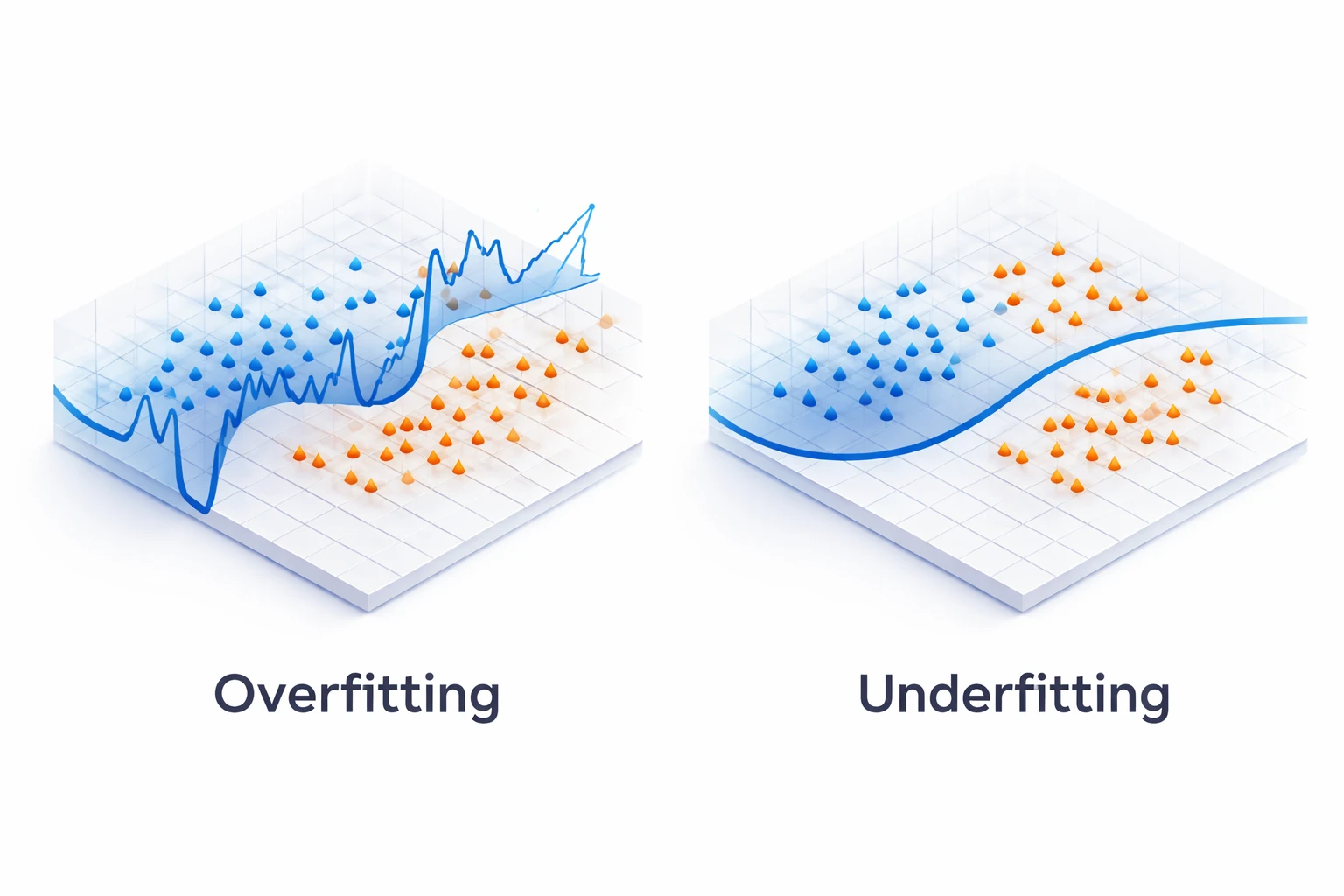
The value of K drastically changes the "decision boundary" — the invisible line separating categories on a map.
Move the slider below to see the effect of different K values:
A very small K (like K=1) makes the model overly sensitive to noise (overfitting). A massive K makes it too generic (underfitting).
Measuring Distance: Euclidean

How do we actually find out who is "nearest"? We need a math formula to calculate distance.
This is the most common metric. It measures the shortest straight-line distance between two points, just like using a ruler on a piece of paper.
Use Euclidean distance for continuous, dense data where points can move freely in any direction.
Measuring Distance: Manhattan

Sometimes a straight line isn't realistic. What if you are navigating a city grid where you can't walk diagonally through buildings?
Hover over the cards below to see the difference:
As the crow flies.
Strictly up/down, left/right.
Knowledge Check
What is the most likely consequence of setting K=1 in a noisy dataset?
The Curse of Dimensionality

KNN is highly susceptible to the "Curse of Dimensionality". As you add more features (dimensions) to your data, the volume of the space increases exponentially.
Choose an outcome below to see why this ruins KNN:
Where is KNN Used?

Despite its flaws with massive data, KNN is brilliant for certain real-world applications where data isn't overwhelmingly huge.
Knowledge Check
Which distance metric is most appropriate for a grid-like layout where diagonal movement is impossible?
Assessment
You've completed the tutorial! Now let's test your knowledge of K-Nearest Neighbors.
There are 5 questions. You need 80% to pass and earn your certificate.
Key Takeaways
- Review the core ideas.
- Connect concepts to practice.
- Prepare for assessment.
Question 1 of 5
What does the "K" in K-Nearest Neighbors represent?
Question 2 of 5
Why is it common practice to choose an odd number for 'K' in a binary classification problem?
Question 3 of 5
If you set K=1 in a noisy dataset, what is the most likely outcome?
Question 4 of 5
When would you prefer Manhattan distance over Euclidean distance?
Question 5 of 5
What does the "Curse of Dimensionality" mean for KNN?